Two properties of graph databases
A graph compute engine is a technology that enables global graph computational algorithms to be run against large datasets.
Performance
Flexibility
Agility
Relational schema for storing customer orders in a customer-centric, transactional application
User Schema
user_id email Phone nameOrder Schema
order_id user_idLine Item
order_id product_id quantityProduct
product_id description handlingThe application exerts a tremendous influence over the design of this schema, making some queries very easy, and others more difficult:
Relational databases struggle with highly connected domains.
Example: Social Domains
Person Schema
ID PersonPersonFriend
PersonID FriendIDBob’s friends Query
SELECT p1.Person
FROM Person p1 JOIN PersonFriend
ON PersonFriend.FriendID = p1.ID
JOIN Person p2
ON PersonFriend.PersonID = p2.ID
WHERE p2.Person = 'Bob'Who is friends with Bob?
SELECT p1.Person
FROM Person p1 JOIN PersonFriend
ON PersonFriend.PersonID = p1.ID
JOIN Person p2
ON PersonFriend.FriendID = p2.ID
WHERE p2.Person = 'Bob'This reciprocal query is still easy to implement, but on the database side it’s more expensive, because the database now has to consider all the rows in the PersonFriend table.
Alice’s friends-of-friends
SELECT p1.Person AS PERSON, p2.Person AS FRIEND_OF_FRIEND
FROM PersonFriend pf1 JOIN Person p1
ON pf1.PersonID = p1.ID
JOIN PersonFriend pf2
ON pf2.PersonID = pf1.FriendID
JOIN Person p2
ON pf2.FriendID = p2.ID
WHERE p1.Person = 'Alice' AND pf2.FriendID <> p1.IDMost NOSQL databases—whether key-value-, document-, or column-oriented— store sets of disconnected documents/values/columns. This makes it difficult to use them for connected data and graphs.
Aggregate stores are not functionally equivalent to graph databases with respect to connected data. Aggregate stores do not maintain consistency of connected data, nor do they support what is known as index-free adjacency, whereby elements contain direct links to their neighbors. As a result, for connected data problems, aggregate stores must employ inherently latent methods for creating and querying relationships outside the data model.
A small social network encoded in an aggregate store
User: Ram
Friends: [Sita]
User: Sita
Friends: [Hanuman, Rohini]
User: Hanuman
Friends: [Ram]
User: Bharat
Friends: [Rohini, Ram]Requires numerous index lookups but no brute-force scans of the entire dataset.
Here friendship isn’t always symmetric."who is friends with Bob?” is difficult rather than “who are Bob’s friends?” because it requires brute-force scan across the whole dataset looking for friends entries that contain Bob.
For above probelm, a graph database provides constant order lookup for the same query. In this case, we simply find the node in the graph that represents Bob, and then follow any incoming friend relationships; these relationships lead to nodes that represent people who consider Bob to be their friend. This is far cheaper than brute-forcing the result because it considers far fewer members of the network; that is, it considers only those that are connected to Bob. Of course, if everybody is friends with Bob, we’ll still end up considering the entire dataset.
To avoid having to process the entire dataset, we could denormalize the storage model by adding backward links. Adding a second property, called perhaps friended_by , to each user, we can list the incoming friendship relations associated with that user. But this doesn’t come for free. For starters, we have to pay the initial and ongoing cost of increased write latency, plus the increased disk utilization cost for storing the additional metadata. On top of that, traversing the links remains expensive, because each hop requires an index lookup. This is because aggregates have no notion of locality, unlike graph databases, which naturally provide index-free adjacency through real—not reified—relationships. By implementing a graph structure atop a nonnative store, we get some of the benefits of partial connectedness, but at substantial cost.
This substantial cost is amplified when it comes to traversing deeper than just one hop. Friends are easy enough, but imagine trying to compute—in real time—friends-of-friends, or friends-of-friends-of-friends.
Many systems try to maintain the appearance of graph-like processing, but inevitably it’s done in batches and doesn’t provide the real-time interaction that users demand.
Relationships in a graph naturally form paths. Querying—or traversing—the graph involves following paths. Because of the fundamentally path-oriented nature of the data model, the majority of path-based graph database operations are highly aligned with the way in which the data is laid out, making them extremely efficient
Graph databases are the best choice for connected data.
Finding extended friends in a relational database versus efficient finding in Neo4j
Depth | RDBMS execution time(s) | Neo4j execution time(s) | Records returned
2 | 0.016 | 0.01 | ~2500
3 | 30.267 | 0.168 | ~110,000
4 | 1543.505 | 1.359 | ~600,000
5 | Unfinished | 2.132 | ~800,000Neo4j’s response time remains relatively flat: just a fraction of a second to perform the query—definitely quick enough for an online system.
One of the most popular structures for representing geospatial coordinates is called an R-Tree. A R-Tree is a graph-like index that describes bounded boxes around geographies. Using such a structure we can describe overlapping hierarchies of locations.Using such a structure we can describe overlapping hierarchies of locations. For example,we can represent the fact that Kakinada is in the India, and that the postal code 533002 is in AP, which is a district in East Godavari, which is in southeastern India, which, in turn, is in India. And because Indian postal codes are fine-grained, we can use that boundary to target people with somewhat similar tastes.
From the data practitioner’s point of view, it’s clear that the graph database is the best technology for dealing with complex, variably structured, densely connected data— that is, with datasets so sophisticated they are unwieldy when treated in any form other than a graph.
Cypher is an expressive (yet compact) graph database query language. In Neo4j, it is usedfor programmatically describing graphs.
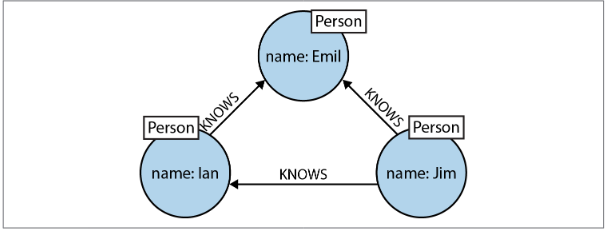
(hanuman)<-[:KNOWS]-(ram)-[:KNOWS]->(sugreev)-[:KNOWS]->(hanuman)Identifiers(ram,hanuman,sugreev) allow us to refer to the same node more than once when describing a pattern.
To bind the pattern to specific nodes and relationships in an existingdataset we must specify some property values and node labels thathelp locate the relevant elements in the dataset. For example:
(hanuman:Person {name:'Hanuman'})
<-[:KNOWS]-(ram:Person {name:'Ram'})
-[:KNOWS]->(sugreev:Person {name:'Sugreev'})
-[:KNOWS]->(hanuman)MATCH (a:Person {name:'Ram'})-[:KNOWS]->(b)-[:KNOWS]->(c),
(a)-[:KNOWS]->(c)RETURN b, c
MATCH (a:Person)-[:KNOWS]->(b)-[:KNOWS]->(c), (a)-[:KNOWS]->(c)
WHERE a.name = 'Ram'
RETURN b, c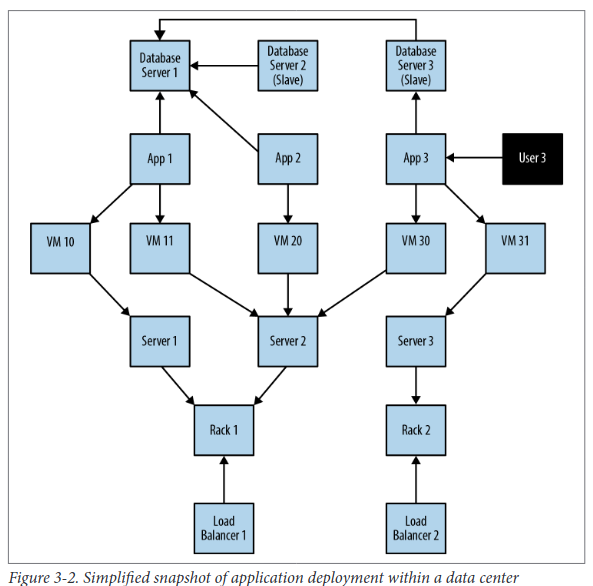
E-R diagrams allow only single, undirected, named relationshipsbetween entities. The relational model is a poor fitfor real-world domains where relationships between entities are both numerous and semantically rich and diverse.
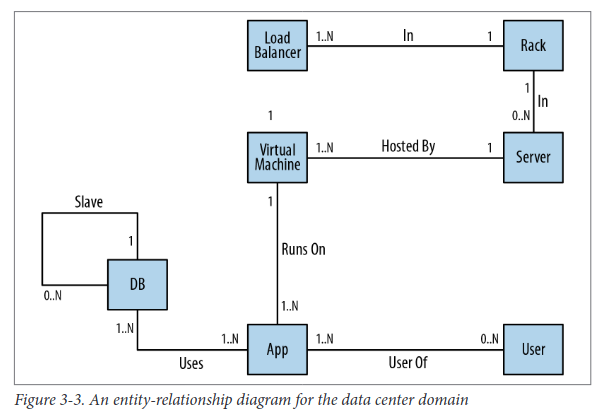
For each entity in our domain, we ensure that we’ve captured its relevant roles as labels, its attributes as properties, and its connections to neighboring entities as relationships.
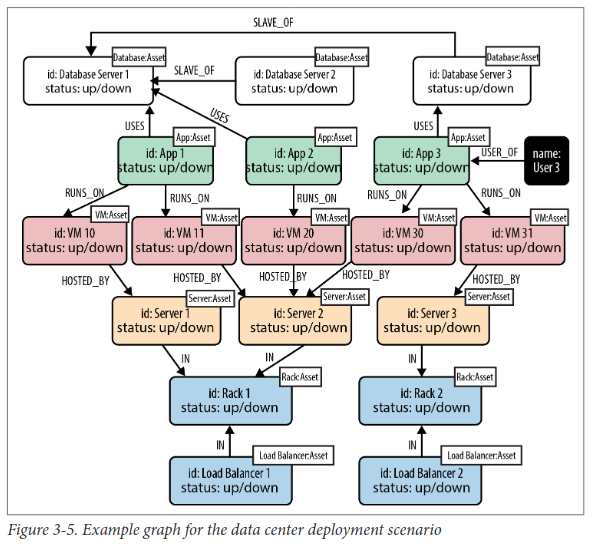
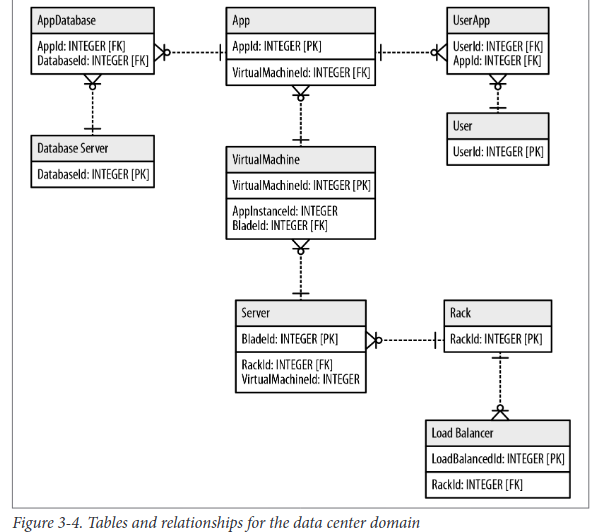
No tables, no normalization, no denormalization. Once we have an accurate representation of our domain model, moving it into the database is trivial.